As the timescale for Sitecore’s built-in indexing reached multitudes of hours rather than minutes, it was time to come up with a new solution. We still needed some of what SOLR was providing in terms of searching by term, but only for back office processes. For the storefront, we were using SOLR more as a view store than any sort of search index. Site search was being provided by a separate provider that utilized the indexing mechanism. That too, would need looking at.
If you’d like to skip the reading and get to the code, you can view the project at https://github.com/jsedlak/petl
Sitecore Indexing Shortcomings
Going back to my first experiences with Sitecore (10+ years ago!), indexing wasn’t at the forefront of my mind. I knew it existed, but I was more interested in writing fancy XSLTs, and the systems we ran on were beefy enough to support it. As time went on and I was exposed to more voluminous websites with more consistently high traffic, indexing slowly became the only thing that mattered.
For an e-Commerce site, having quick access to reliable product information is vital. Faster page loads with more precise pricing and inventory information means a higher purchase rate. It’s really as simple as that, at least from a backend developer’s perspective.
But as your catalog grows, indexing runs into a serious problem. It has to run through every item in every language and decide what to do with it, based on your configuration. And while there are ways to narrow the search path, or trim out some of the fat, it will never be as precise as, say, a hardcoded DTO instantiation would be. Consider the following brief example, where we generate a Product object from a Sitecore item.
var productItem = Context.Database.GetItem("{some guid}");
var product = new Product {
Title = productItem.DisplayName,
Description = productItem["Product Description"],
// ...
}
The lack of instantiation of various “computed field” objects alone saves time, but moreso we know what we have in hand and what we want to achieve. This is something that Sitecore Indexing simply cannot do. It has to loop through the computed fields and figure out if they need to run. It has to map configuration to each item. Worst case scenario, it looks at an item that doesn’t matter and still does all that work.
While Sitecore Indexing still has its uses, we needed something with more precision and control. Something the developers knew would work day in and day out.
What then?
The answer is rather simple – take the hardcoded version above, and make it generic. Keep it configured via code to be as close to hardcoded as possible, but allow for variance in how data is transferred from Sitecore Item to Product object. And because we’re dealing with a custom object, we can store it easily in more than one location.
What we came up with was a simple mechanism that takes an input, runs through a series of configured evaluations, and produces an output.
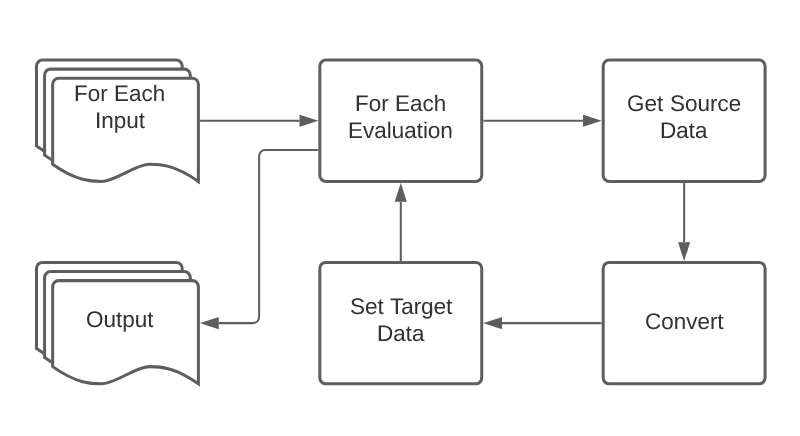
With this established, we need to wrap it with a mechanism that can automate the item selection and output saving processes.
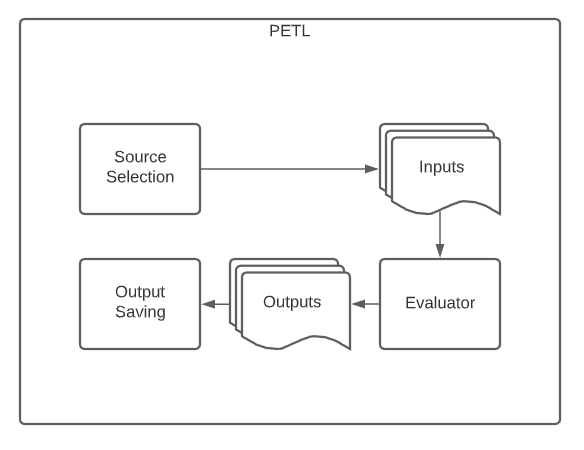
Using this architecture as the basis, we provide the following:
- A fluent interface for configuring the evaluations
- An ability to change the set of evaluations per input
- An ability to alter how exceptions and other unforeseen issues are handled internally
- A DI context for the evaluations to allow for testability
- A user interface for manually evaluating items
- Automated evaluation via event driven approach
Building Petl Inside Out
I often build software from smallest piece to biggest piece, especially if I’ve got a good sense of what the overall architecture is going to look like. In the case of Petl, this would consist of the Evaluator and the pieces required to process an item.
Let’s start with the workflow – the Evaluator needs to…
- Determine what set of sources apply to the input
- Obtain a reference to a matching target
- Apply those sources and any related converters and targets
- Return the target
This turns into the following…
public class Evaluator {
public TOutput Eval<TInput, TOutput>(
TInput input,
EvalOptions options) {
// ... ensure options is valid
var context = new EvalContext<TInput, TOutput>
{
Options = options,
Source = input
};
// activate the context, providing an output
options.Activator.Activate(context);
var matchingSets = _evalSets
.Where(m => m is EvalSet<TInput, TOutput>)
.Select(m => m as EvalSet<TInput, TOutput>);
foreach (var set in matchingSets)
{
if (!set.CanHandle(input))
{
continue;
}
set.Evaluate(context);
return context.Target;
}
return context.Target;
}
}
Fancy, right? We’re hiding some workload in the Activate method, so let’s take a look at that. It can be passed in through the options, or fall back to a simple reflection based activator. This class & method is responsible for finding or creating an output object.
public class ReflectionActivator : IActivator
{
public void Activate<TInput, TOutput>(EvalContext<TInput, TOutput> context)
{
context.Target = Activator.CreateInstance<TOutput>();
}
}
After Activation, you can see the code immediately jumps into looking for a matching set and evaluates the first one that can be handled. The EvalSet is the first part of the codebase that exposes the fluent topology, and represents the top level of that decision tree.
The Fluent Interface
For any fluent interface, it’s important to understand the hierarchy of calls that can be made and on which objects those calls can live. Fortunately for Petl, the tree is fairly linear. Eval Sets have Sources, Sources have Targets, and Targets have Converters.
To support adding sources to Eval Sets, we’ll start with the ICanAddSource interface.
public interface ICanAddSource<TInput, TOutput>
{
ICanAddTarget<TInput, TOutput> AddSource(ProgrammableSource<TInput, TOutput> source);
}
You’ll notice that this particular interface progresses the fluent interface down a level, returning an ICanAddTarget object. For each time we progress down the tree, the functionality should narrow in scope, as it pertains to the structure of the object tree. In practical terms, this means the ICanAddTarget interface should not allow us to add sources.
public interface ICanAddTarget<TInput, TOutput>
{
ICanAddTarget<TInput, TOutput> AddTarget(ProgrammableTarget<TInput, TOutput> target, Action<ICanAddConverter> configure = null);
}
This is actually the bottom of the fluent tree. While we could go one step further and return an ICanAddConverter interface, it would stop developers from easily adding multiple targets. Instead, the code returns an ICanAddTarget object, allowing multiple targets to easily be assigned to a single source, while allowing for the configuration of one or more converters per target.
public interface ICanAddConverter
{
ICanAddConverter AddConverter(IValueConverter valueConverter);
}
The ICanAddConverter interface is a simple looping interface much like ICanAddTarget, allowing dot-chaining of converter additions.
Now that we have the fluent interface designed, we just need to provide abstract/concrete class implementations of all the interfaces and finish them off with a “Builder” concrete at the top to collect and compile all the information.
For brevity, I’m going to skip over the creation of these classes. If you’d like to see more, you may continue reading in the source repo at https://github.com/jsedlak/petl
Building an Expression Source
Building a source that maps to an expression tree actually turns out to be quite simple. We just need to compile the expression and execute it against the input item.
public sealed class ExpressionProgrammableSource<TInput, TOutput> : ProgrammableSource<TInput, TOutput>
{
private readonly Expression<Func<TInput, object>> _expression;
public ExpressionProgrammableSource(Expression<Func<TInput, object>> expression, IEnumerable<ProgrammableTarget<TInput, TOutput>> targets = null)
: base(targets)
{
_expression = expression;
}
protected override object GetValue(EvalContext<TInput, TOutput> context)
{
var func = _expression.Compile();
return func(context.Source);
}
}
To enable some syntactical sugar, we’ll build an extension method that supports adding this source to the EvalSet via a familar “With/From/To” method syntax.
public static class ExpressionSourceExtensions
{
public static ICanAddTarget<TInput, TOutput> FromExpression<TInput, TOutput>(
this ICanAddSource<TInput, TOutput> evalSet,
Expression<Func<TInput, object>> expression)
{
var source = new ExpressionProgrammableSource<TInput, TOutput>(expression);
evalSet.AddSource(source);
return source;
}
}
You may also wish to add an attribute that does much the same, supported via an “AutoMap” method on the Builder class. I’ll leave that for another time, however.
Building an Expression Target
Now that we have a Programmable Source that can pull data out of an expression tree, we need to support the opposite – putting data into an expression tree.
This one is a tad bit more complex as it has to walk the expression tree and build or otherwise figure out what the developer is really trying to get at. For that purpose, we’ll build an extension method that returns the object we need to act on as well as the PropertyInfo we need to target.
public static Tuple<object, PropertyInfo> GetPropertyInfo<TEntity>(
this Expression<Func<TEntity, object>> entityExpression,
TEntity entity)
{
var members = new List<MemberExpression>();
var expression = entityExpression.Body;
while (expression != null)
{
var memberExpression = (MemberExpression)null;
if (expression.NodeType == ExpressionType.Convert)
{
memberExpression = ((UnaryExpression)expression).Operand as MemberExpression;
}
else if (expression.NodeType == ExpressionType.MemberAccess)
{
memberExpression = expression as MemberExpression;
}
if (memberExpression == null)
{
break;
}
members.Add(memberExpression);
expression = memberExpression.Expression;
}
// the expression tree comes in linearly backwards (from right to left)
members.Reverse();
object current = entity;
var currentProperty = (PropertyInfo)null;
for (var i = 0; i < members.Count; i++)
{
var exp = members[i];
currentProperty = current.GetType().GetProperty(exp.Member.Name);
// the last expression we actually want to just return
// blah.child.property => { current = child, property = property }
if (i == members.Count - 1)
{
break;
}
// otherwise, we need to try and go deeper
var currentValue = currentProperty.GetValue(current);
// do we need to create the instance so that we may go deeper?
if (currentValue == null)
{
currentValue = Activator.CreateInstance(currentProperty.PropertyType);
currentProperty.SetValue(current, currentValue);
}
current = currentValue;
}
return new Tuple<object, PropertyInfo>(current, currentProperty);
}
The Expression Programmable Target class then becomes a simple matter of obtaining those references via the extension method and using them to set the incoming value.
public sealed class ExpressionProgrammableTarget<TInput, TOutput> : ProgrammableTarget<TInput, TOutput>
{
private readonly Expression<Func<TOutput, object>> _expression;
public ExpressionProgrammableTarget(Expression<Func<TOutput, object>> expression)
{
_expression = expression;
}
protected override void SetValue(EvalContext<TInput, TOutput> context, object value)
{
var expressionInfo = _expression.GetPropertyInfo(context.Target);
expressionInfo.Item2.SetValue(expressionInfo.Item1, value);
}
}
Putting It All Together
Provided we’ve wired everything up correctly, we should now have a way to migrate data from one expression in an input object to an expression in an output object. This is where unit tests come in handy!
[TestMethod]
public void CanUseBuilderForMemberToMember()
{
var builder = new EvaluatorBuilder();
builder
.WithActivator(new ReflectionActivator())
.Map<Foo, Bar>(m => true)
.FromExpression(m => m.Message)
.ToExpression(m => m.Content);
var evaluator = builder.Build();
var output = evaluator.Evaluate<Foo, Bar>(new Foo { Message = "Hello, world!" });
Assert.IsNotNull(output);
Assert.IsTrue(output.Content.Equals("Hello, world!", System.StringComparison.OrdinalIgnoreCase));
}
In the above test, we’re using the Builder pattern and the fluent interface to construct our Evaluator object. We use the extension methods “FromExpression” and “ToExpression” to hide how we construct the various internal objects. We then evaluate an input “Foo” object and expect a correctly evaluated “Bar” object to be returned.
What’s Next?
Obviously, this is just scratching the surface of what this architecture can do, and how I’ve used it in production. To recap, we’ve accomplished the following:
- Built a testable, developer driven architecture for moving data between two object types
- Built a basic fluent interface to improve readability
- Implemented Expression Source and Target classes as examples
- Provided basic unit testing to prove the methodology works
To make this really shine, we will need to add a few more pieces of tech.
- Add flow control to handle exceptions and other issues
- Add tighter integration with Sitecore to support Items, Fields, and other Sitecore related sources
- Add the top level “Finding” & “Saving” pieces to support things like finding an existing Sitecore Item as a target, or saving to a SOLR index.
- Add support for external sources via Dependency Injection
For now, I hope this gets you into thinking what is possible.